|
|
@@ -0,0 +1,477 @@
|
|
|
+---
|
|
|
+marp: true
|
|
|
+theme: uncover
|
|
|
+paginate: false
|
|
|
+size: 16:9
|
|
|
+backgroundColor: #f4f5f7
|
|
|
+color: #1f2933
|
|
|
+style: |
|
|
|
+ section {
|
|
|
+ font-size: 1.9em;
|
|
|
+ }
|
|
|
+
|
|
|
+ h1, h2, h3 {
|
|
|
+ color: #0f172a;
|
|
|
+ }
|
|
|
+
|
|
|
+ /* Texto secundario */
|
|
|
+ p, li {
|
|
|
+ color: #1f2933;
|
|
|
+ }
|
|
|
+
|
|
|
+ /* Cajas destacadas */
|
|
|
+ .box {
|
|
|
+ border: 3px solid #2563eb;
|
|
|
+ padding: 1em;
|
|
|
+ border-radius: 12px;
|
|
|
+ background-color: #e0e7ff;
|
|
|
+ color: #1e293b;
|
|
|
+ }
|
|
|
+
|
|
|
+
|
|
|
+ .columns {
|
|
|
+ display: flex;
|
|
|
+ gap: 1em;
|
|
|
+ justify-content: center;
|
|
|
+ align-items: stretch;
|
|
|
+ }
|
|
|
+
|
|
|
+
|
|
|
+ .box.warning {
|
|
|
+ border-color: #f97316;
|
|
|
+ background-color: #ffedd5;
|
|
|
+ }
|
|
|
+
|
|
|
+ /* Alineación */
|
|
|
+ .left {
|
|
|
+ text-align: left;
|
|
|
+ }
|
|
|
+
|
|
|
+ /* Código */
|
|
|
+ pre, code {
|
|
|
+ background-color: #e5e7eb;
|
|
|
+ color: #111827;
|
|
|
+ }
|
|
|
+ .w-30 { width: 30%; }
|
|
|
+ .w-40 { width: 40%; }
|
|
|
+ .w-50 { width: 50%; }
|
|
|
+ .w-60 { width: 60%; }
|
|
|
+ .w-70 { width: 70%; }
|
|
|
+ .w-80 { width: 80%; }
|
|
|
+ .center {
|
|
|
+ margin-left: auto;
|
|
|
+ margin-right: auto;
|
|
|
+ }
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+# Spring Data
|
|
|
+
|
|
|
+### Capa de persistencia relacional
|
|
|
+
|
|
|
+>Un paseo (de 2h) buceando en código
|
|
|
+
|
|
|
+<br/>
|
|
|
+<br/>
|
|
|
+
|
|
|
+##### Daniel García Costa
|
|
|
+###### 2026
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## ¿Que vamos a ver?
|
|
|
+
|
|
|
+- **¿Que es Spring Data?**
|
|
|
+- **Modelo de dominio**
|
|
|
+- **Consultas en Spring Data**
|
|
|
+ - Métodos de abstracción
|
|
|
+ - JPQL
|
|
|
+ - SQL nativo
|
|
|
+- **Rendimiento**
|
|
|
+- **Optimizaciones**
|
|
|
+- **Sistema de ejemplo**
|
|
|
+- **Mucho código**
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## ¿Qué es Spring Data?
|
|
|
+
|
|
|
+Spring Data es el paquete del ecosistema Spring para **acceder a datos de forma consistente**.
|
|
|
+
|
|
|
+- Define un modelo común de acceso a datos
|
|
|
+- Orquesta todo lo relacionado con el acceso a datos
|
|
|
+- Reduce código repetitivo
|
|
|
+- Se integra con distintos motores
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Qué NO es Spring Data
|
|
|
+
|
|
|
+Spring Data:
|
|
|
+
|
|
|
+- ❌ No elimina el modelo relacional
|
|
|
+- ❌ No es ni sustituye al ORM
|
|
|
+- ❌ No optimiza consultas automáticamente
|
|
|
+- ❌ No toma decisiones por nosotros
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-90 center">
|
|
|
+Facilita el acceso a datos, pero <strong>las decisiones siguen siendo nuestras</strong>.
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Capas de Spring Data
|
|
|
+
|
|
|
+**Aplicación**
|
|
|
+↓
|
|
|
+**Spring Data** — Abstracción de repositorios
|
|
|
+<small>Abstracción para definir repositorios y consultas</small>
|
|
|
+↓
|
|
|
+**JPA** — API estándar de persistencia
|
|
|
+<small>Especificación estándar (interfaces y anotaciones)</small>
|
|
|
+↓
|
|
|
+**Hibernate** — ORM (Object–Relational Mapping)
|
|
|
+<small>Traducción y mapeo de objetos a SQL</small>
|
|
|
+↓
|
|
|
+**JDBC Driver** — Comunicación con la base de datos
|
|
|
+<small>Ejecuta SQL contra la base de datos</small>
|
|
|
+↓
|
|
|
+**Base de datos**
|
|
|
+
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Idea clave
|
|
|
+
|
|
|
+Spring Data facilita el acceso a datos pero **no elimina el modelo relacional**.
|
|
|
+
|
|
|
+- Las queries siguen existiendo
|
|
|
+- El SQL sigue ejecutándose
|
|
|
+- Las decisiones siguen importando
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Modelo relacional
|
|
|
+
|
|
|
+La base de datos trabaja con:
|
|
|
+
|
|
|
+- Tablas
|
|
|
+- Filas
|
|
|
+- Claves primarias y ajenas
|
|
|
+- Tipos simples
|
|
|
+- Operaciones SQL
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-60 center">
|
|
|
+La lógica es <strong>estructural y declarativa</strong>.
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Modelo de dominio
|
|
|
+
|
|
|
+La aplicación trabaja con:
|
|
|
+
|
|
|
+- Objetos
|
|
|
+- Relaciones entre entidades
|
|
|
+- Comportamiento
|
|
|
+- Identidad lógica
|
|
|
+- Reglas de negocio
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-50 center">
|
|
|
+La lógica es <strong>orientada a objetos</strong>.
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## El problema central
|
|
|
+
|
|
|
+- El modelo relacional ≠ modelo de dominio
|
|
|
+- Los objetos no son filas
|
|
|
+- Las relaciones no son joins directos
|
|
|
+- El rendimiento no es transparente
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-50 center">
|
|
|
+<strong>¡Necesitamos una capa intermedia!</strong>.
|
|
|
+</div>
|
|
|
+
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## ¿Qué consultamos en Spring Data?
|
|
|
+
|
|
|
+En Spring Data **no consultamos tablas**.
|
|
|
+
|
|
|
+Consultamos:
|
|
|
+
|
|
|
+- Entidades de dominio
|
|
|
+- Gestionadas por JPA
|
|
|
+- Mapeadas a tablas relacionales
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Entidad como contrato
|
|
|
+
|
|
|
+Una entidad define:
|
|
|
+
|
|
|
+- Qué datos existen
|
|
|
+- Cómo se relacionan
|
|
|
+- Cómo se identifican
|
|
|
+- Cómo se persisten
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-70 center">
|
|
|
+<strong>La base de datos queda detrás de ese contrato</strong>.
|
|
|
+</div>
|
|
|
+<br>
|
|
|
+*Usamos anotaciones para definir las propiedades y relaciones de nuestras entidades. Pej. @Entity, @Table, @Id, @Column, ...*
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## ¿Dónde queda el SQL?
|
|
|
+
|
|
|
+Aunque trabajemos con entidades:
|
|
|
+
|
|
|
+- SQL sigue existiendo
|
|
|
+- Hibernate lo genera o lo ejecuta
|
|
|
+- La base de datos decide el coste (planificador del SGBD)
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-80 center">
|
|
|
+Spring Data <strong>te abstrae de las consultas</strong> pero <strong>no las elimina</strong>.
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Repository
|
|
|
+
|
|
|
+Un Repository es:
|
|
|
+
|
|
|
+- Una abstracción
|
|
|
+- Orientada al dominio
|
|
|
+- Tipada con entidades
|
|
|
+- Independiente del motor SQL
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-70 center">
|
|
|
+Es la <strong>frontera</strong> entre la aplicación y la persistencia.
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Tres formas de consultar datos
|
|
|
+
|
|
|
+En Spring Data podemos consultar usando:
|
|
|
+
|
|
|
+1. Métodos de abstracción del Repository
|
|
|
+2. JPQL (`@Query`)
|
|
|
+3. SQL nativo (`nativeQuery`)
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box warning w-30 center">
|
|
|
+
|
|
|
+**A mayor abstracción:**
|
|
|
+- Menos control
|
|
|
+- Más conveniencia
|
|
|
+
|
|
|
+**A menor abstracción:**
|
|
|
+- Más control
|
|
|
+- Más responsabilidad
|
|
|
+
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Rendimiento
|
|
|
+
|
|
|
+Cuando trabajamos con bases de datos:
|
|
|
+
|
|
|
+- Todas las consultas tienen coste
|
|
|
+- El volumen de datos importa
|
|
|
+- La abstracción no es gratuita
|
|
|
+<br>
|
|
|
+<div class="box w-80 center">
|
|
|
+El rendimiento depende de <strong>cómo accedemos a los datos</strong>
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## ¿La abstracción es más lenta?
|
|
|
+
|
|
|
+Pues... No siempre.
|
|
|
+
|
|
|
+Depende de:
|
|
|
+- La consulta
|
|
|
+- El volumen de datos
|
|
|
+- El uso de entidades o proyecciones
|
|
|
+- El trabajo extra del ORM
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-90 center">
|
|
|
+El problema no es la abstracción, es lo <strong>qué se pide a la base de datos</strong>.
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Costes ocultos habituales
|
|
|
+
|
|
|
+- Cargar entidades completas
|
|
|
+- Inicializar relaciones
|
|
|
+- Consultas innecesarias
|
|
|
+- `N+1 SELECT`
|
|
|
+- Transferencia de datos excesiva
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-90 center">
|
|
|
+Muchos problemas no vienen del SQL, sino del <strong>modelo de acceso</strong>.
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+### Ejemplo N+1 SELECT
|
|
|
+```
|
|
|
+
|
|
|
+SELECT t1.*, t2.*, ((t1.actual/t2.total)*100) DIV 1 AS progreso,
|
|
|
+ CASE WHEN t1.actual = t2.total AND t1.nbpar = t2.total AND t1.nbcomp = 1 THEN 'bg-success'
|
|
|
+ WHEN actual > 0 AND t1.fact <> factorial(actual) AND t1.nbcomp = 1 THEN 'bg-success'
|
|
|
+ WHEN t1.nbpar = t2.total AND t1.nbcomp = 0 THEN 'bg-danger'
|
|
|
+ WHEN actual > 0 AND t1.fact = factorial(actual) THEN 'bg-info'
|
|
|
+ WHEN actual > 0 AND t1.fact <> factorial(actual) AND t1.nbcomp = 0 THEN 'bg-warning'
|
|
|
+ WHEN t1.discard = 1 THEN 'bg-secondary'
|
|
|
+ ELSE 'text-black'
|
|
|
+ END AS class,
|
|
|
+ CASE
|
|
|
+ WHEN t1.actual = t2.total AND t1.nbpar < t2.total AND t1.nbcomp = 1 THEN '*'
|
|
|
+ ELSE ''
|
|
|
+ END AS aux
|
|
|
+ FROM
|
|
|
+ (SELECT al.usuario, al.id_alumno, al.observaciones AS obs, al.muerto AS discard, MAX(n_problema) AS actual,
|
|
|
+ CAST(SUM(CASE WHEN completa = 0 THEN 1 ELSE 0 END) AS SIGNED) AS nbpar,
|
|
|
+ CAST(SUM(CASE WHEN completa = 1 THEN 1 ELSE 0 END)AS SIGNED) AS nbcomp,
|
|
|
+ SUM(n_problema) AS fact
|
|
|
+ FROM awpsolver.resultados_json rj
|
|
|
+ LEFT JOIN awpsolver.alumnos al ON al.id_alumno = rj.id_alumno
|
|
|
+ WHERE rj.id_grupo_experimento = :v
|
|
|
+ GROUP BY al.usuario, al.id_alumno
|
|
|
+ UNION
|
|
|
+ SELECT al.usuario, al.id_alumno, al.observaciones AS obs, al.muerto AS discard, 0 AS actual,
|
|
|
+ 0 AS nbpar, 0 AS nbcomp, 0 AS self_fact
|
|
|
+ FROM awpsolver.alumnos al
|
|
|
+ LEFT JOIN grupos_experimentos ge ON al.id_grupo = ge.id_grupo
|
|
|
+ WHERE ge.id_grupo_experimento = :v AND al.id_alumno NOT IN(
|
|
|
+ SELECT id_alumno FROM awpsolver.resultados_json WHERE id_grupo_experimento = :v)
|
|
|
+ ORDER BY 2) AS t1,
|
|
|
+ (SELECT COUNT(*) AS total, factorial(COUNT(*)) AS fact FROM awpsolver.problemas WHERE id_experimento
|
|
|
+ IN(SELECT id_experimento FROM awpsolver.grupos_experimentos WHERE id_grupo_experimento = :v)) AS t2;
|
|
|
+```
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## JPQL vs SQL nativo
|
|
|
+
|
|
|
+Ambos ejecutan SQL.
|
|
|
+
|
|
|
+Diferencias:
|
|
|
+- JPQL prioriza el modelo de dominio
|
|
|
+- SQL nativo prioriza el modelo relacional
|
|
|
+- El control es distinto
|
|
|
+
|
|
|
+<br>
|
|
|
+<div class="box w-90 center">
|
|
|
+El rendimiento depende más de la query que del lenguaje.
|
|
|
+</div>
|
|
|
+
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Algunas técnicas para reducir coste
|
|
|
+
|
|
|
+**Queries específicas**
|
|
|
+Aprovecha la potencia de la BD no tengas miedo a escribir 100 lineas de SQL
|
|
|
+
|
|
|
+**Proyecciones**
|
|
|
+Traer solo lo necesario (tablas intermedias, vistas materizalidas, ...).
|
|
|
+
|
|
|
+**Agregados**
|
|
|
+(`COUNT`, `SUM`, `AVG`) sobre el SGBD y no en dominio
|
|
|
+
|
|
|
+**Paginación real**
|
|
|
+Traer solo lo necesario, no todo + filtro posterior
|
|
|
+<br>
|
|
|
+<div class="columns">
|
|
|
+ <div class="box warning w-50 center">
|
|
|
+
|
|
|
+ - Menos columnas = Menos memoria
|
|
|
+ - Menos trabajo del ORM
|
|
|
+ - Menos transferencia de datos
|
|
|
+ </div>
|
|
|
+ <div class="box w-40 center">
|
|
|
+ <strong>Son la primera herramienta antes de optimizar consultas.</strong>
|
|
|
+ </div>
|
|
|
+</div>
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Y todo eso... ¿como lo vemos?
|
|
|
+
|
|
|
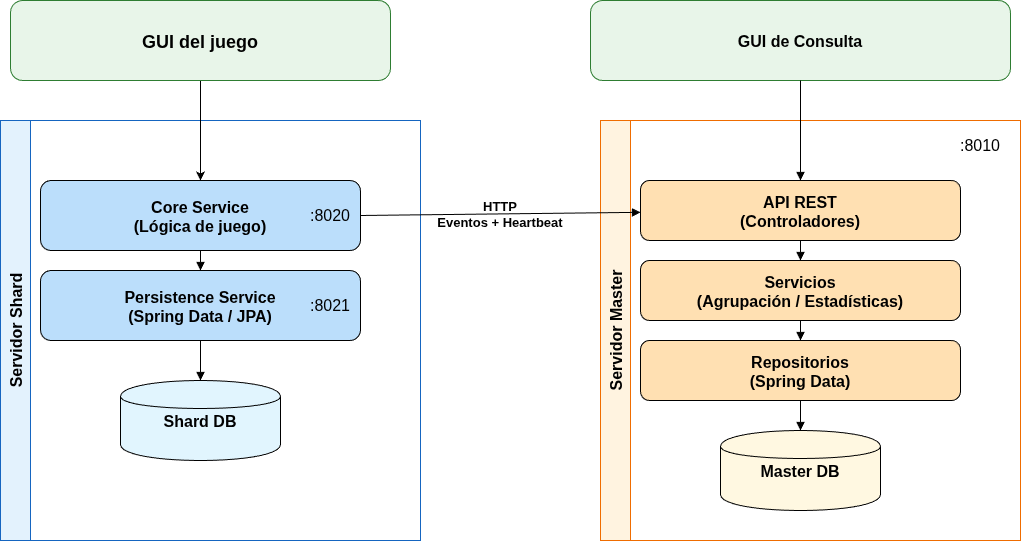
+Simulación de un juego de estrategia MMO (multijugador masivo en línea) multimundo.
|
|
|
+<br>
|
|
|
+- **Servidor Shard (mundo)**
|
|
|
+ - Aloja jugadores
|
|
|
+ - Contiene la dinámica del juego
|
|
|
+ - Reenvía los eventos al Master
|
|
|
+<br>
|
|
|
+- **Servidor Master (coordinador)**
|
|
|
+ - Recibe eventos de los Shard, consulta estados, jugadores, rankings, etc.
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Arquitectura
|
|
|
+
|
|
|
+- **Servidor Master**
|
|
|
+ - Monolítico (un único servicio)
|
|
|
+ - División lógica en controladores -> servicios -> repositorios
|
|
|
+ - Solo recibe y agrega información
|
|
|
+ - GUI de consulta
|
|
|
+<br>
|
|
|
+- **Servidor Shard**
|
|
|
+ - Dos servicios (Persistence + Core)
|
|
|
+ - Gestiona los eventos de los jugadores
|
|
|
+ - GUI para simular jugadores
|
|
|
+ - Reenvío de eventos a Master
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## ¿Por qué esta arquitectura?
|
|
|
+
|
|
|
+- Separación clara de responsabilidades
|
|
|
+- Escalado horizontal de shards
|
|
|
+- Aislamiento del dominio de juego
|
|
|
+- Centralización de analítica
|
|
|
+- Escenario realista para estudiar consultas
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+---
|
|
|
+
|
|
|
+## Clona los siguientes proyectos
|
|
|
+
|
|
|
+- **Master**
|
|
|
+ - https://inmaculados.uv.es/dagarcos/PSIM-master
|
|
|
+<br>
|
|
|
+- **Shard(s)**
|
|
|
+ - https://inmaculados.uv.es/dagarcos/PSIM-shard-core
|
|
|
+ - https://inmaculados.uv.es/dagarcos/PSIM-shard-persistence
|
|
|
+
|
|
|
+<br>
|
|
|
+
|
|
|
+#### Y ahora... ¡a ver código!
|


{kind=link}